Overview
- optimization problem
- representer theorem
- kernels
- example of kernels
In optimal margin classifier, we want to find the decision boundary parameterized by w and b that maximizes the geometric margin.
\[\max _{\gamma, w, b} \gamma
\begin{array}{ll}
\text { s.t. } & y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq \gamma, \quad i=1, \ldots, n \\
& \|w\|=1
\end{array}
\]
If we choose \(||w|| = \frac 1 \gamma\)
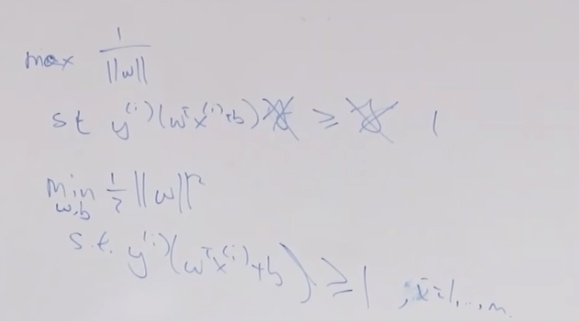
\[\begin{aligned}
\min _{w, b} & \frac{1}{2}\|w\|^{2} \\
\text { s.t. } & y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq 1, \quad i=1, \ldots, n
\end{aligned}
\]
What we assume is
\[w = \sum^m_{i=1} \alpha_i y^{(i)} x^{(i)}
\]
The w can be expressed as linear combination of the training examples. \(y^{(i)} = \pm1\)
The representor theorem will prove we can make this assumption without losing any performance.
Intuition 2 of representor theorem
w set the direction of decision boundary, and we set different b to move decision boundary back and forth.
Let's assume \(w = \sum^m_{i=1} \alpha_iy^{(i)}x^{(i)}\)
\[\begin{aligned}
\min _{w, b} & \frac{1}{2}\|w\|^{2} = \frac 1 2 w^Tw\\
\text { s.t. } & y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq 1, \quad i=1, \ldots, n
\end{aligned}
\]
That is to say, we are going to solve
\[\begin{aligned}
& \min _{w, b} \frac 1 2 (\sum^m_{i=1} \alpha_iy^{(i)}x^{(i)})^T ( \sum^m_{i=1} \alpha_iy^{(i)}x^{(i)})\\
= &\min _{w, b} \frac 1 2 \sum_i \sum_j \alpha_i \alpha_j y^{(i)} y^{(j)}{x^{(i)}}^T x^{(i)}
\end{aligned}
\]
In which \({x^{(i)}}^T x^{(i)}\) can be represented as \(<x^{(i)}, x^{(j)}>\).
\(<x^{(i)}, x^{(j)}> = x^Tz\) is the inner products.
The constraint \( y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq 1\) will become
\[\begin{aligned}
y^{(i)}\left({\left(\sum^m_{i=1} \alpha_iy^{(i)}x^{(i)}\right)}^{T} x^{(i)}+b\right) \geq 1 \\
y^{(i)}\left(\sum^m_{i=1} \alpha_iy^{(i)}<x^{(j)}, x^{(i)}>+b\right) \geq 1
\end{aligned}
\]
Dual Optimization Problem
\[\begin{aligned}
\max _{\alpha} & W(\alpha)=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} y^{(i)} y^{(j)} \alpha_{i} \alpha_{j}\left\langle x^{(i)}, x^{(j)}\right\rangle \\
\text { s.t. } & \alpha_{i} \geq 0, \quad i=1, \ldots, n \\
& \sum_{i=1}^{n} \alpha_{i} y^{(i)}=0
\end{aligned}
\]
Which can be simplified from the one above by convex optimization theory.
Kernal Trick
- Write algorithm in terms of \(<x^{(i)}, x^{(j)}>\).
- Let there be mapping from x to \(\phi(x)\).

x may be 1D or 2D, but \(\phi(x)\) would be 100,00 D or even infinite dimension.
- Find a way to compute \(K(x,z) = \phi(x)^T\phi(z)\)
- Replace <x,z> in algorithm with K(x,z )
One example of kernal
SVM
SVM = optimal classifier + kernel trick
How to make kernels?
- If x, z are similar, \(K(x,z) = \phi(x)^T\phi(z)\) is large.
- The inner product of two vectors direction is similar is large.
- If x, z are dissimilar, \(K(x,z) = \phi(x)^T\phi(z)\) is small.
If we think kernel funtion as a similarity measure function, we can have another measure function. **Gaussian Kernel **
\[K(x, z)=\exp \left(-\frac{\|x-z\|^{2}}{2 \sigma^{2}}\right)
\]
Linear Kernel \(K(x,z) = x^Tz, \phi(x)= x\)
Gaussian Kernel \(\phi(x)\in \mathbb{R}^\infty\)
