
This algorithm is presented to convert mass distance networks to this tree structure.
This method is useful for both regular untargeted metabolomics and stable isotope tracing experiments.
The term ""annotation in metabolomics often includes:
- The assignment of measured ions to their original compounds. (pre-annotation)
- Establishing the identity of the compounds.
Those from the same original compound should have the same retention time in chromatography.
Most pre-annotation tools use a network representation of degenerate peaks.
The main challenge remains to resolve how all peaks are generated from the same original compound, which requires:
- Inferring the neutral mass of the original compound
- Establish the relationship of all peaks to the original compound.
Result
The adducts can be represented as a tree, using the neutral form as the root. Using isotopes as leaves to the adducts.
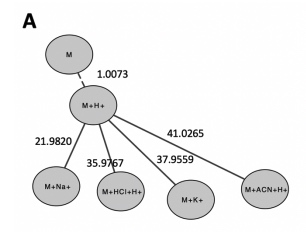
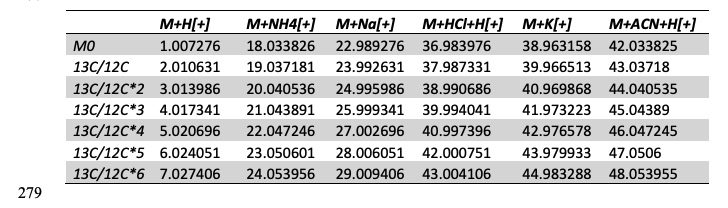
Therefore, the combination of isotopes and adducts, as exemplified in Table 1, can be represented as a 2-tier tree. The tree can either use adducts as tier 1 or isotopes as tier 1.
Algorithm converting a mass distance network to a 2-tier tree
One key observation is that all ions connected by isotopic edges belong to the same adduct. Thus. subnetwork per adduct can be defined from a mass distance network.
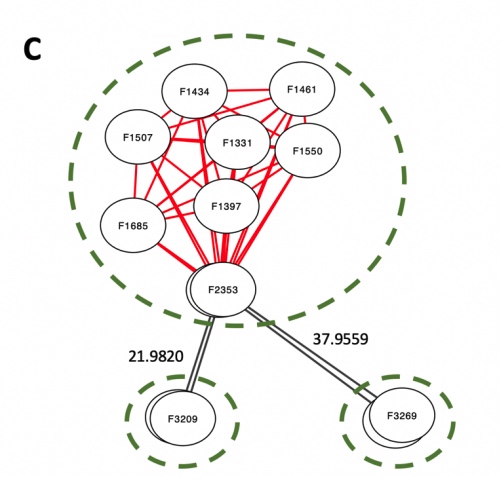
Once these isotopic subnetworks are abstracted into individual network nodes, we can find the best alignment between this abstracted network and the adduct tree.
Two steps:
- Obtain a tree with optimal number of ions explained in the alignment of adduct trees.
- Then in the alignment of isotopes.
Results:

To match ths 2-tier tree structure, the networks have to become DAG.Erroneous edges are weeded out because they do not satisfied DAG and a rooted tree.
Based on the matched m/z values, the neutral mass of M0 compound is obtained by a regression model.
Once the core structure of a tree is established, additional adducts and fragments can be searched in the data.
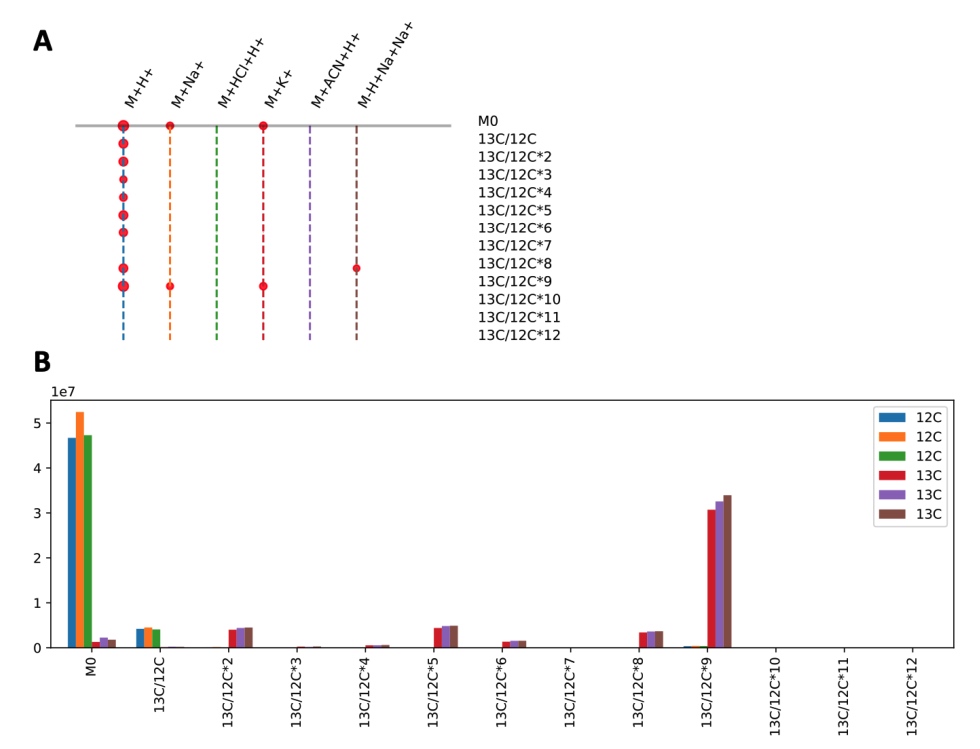
A is a "khipu" for one empirical compound. B is the first "rope" of A.